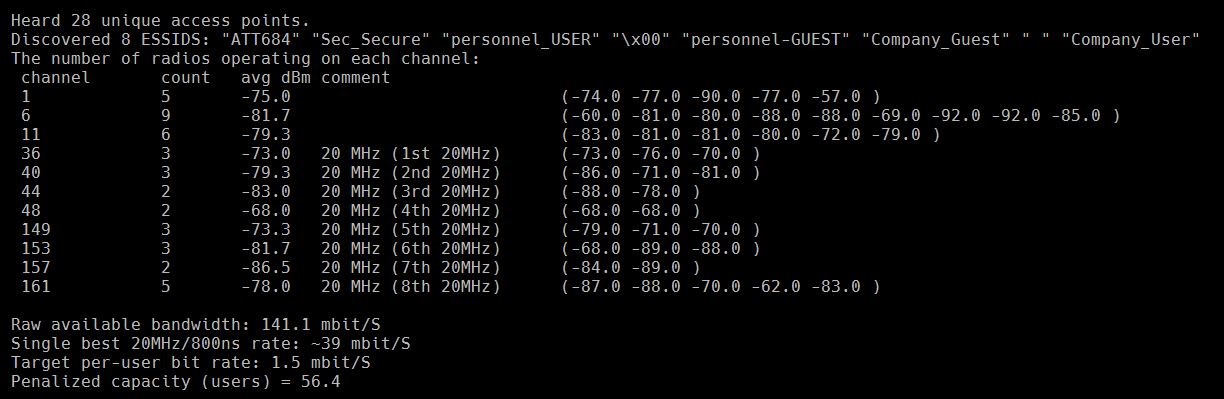
AI in your network
There's a scene in "Mars Attacks" where Pierce Brosnan, playing the scientist, dissects one of the dead Martians. He pulls some red jelly from the brain and says "Curious." It captures one of the problems with what we're calling AI today because like the components of an AI, though the jelly can do amazing things, you really can't look at it and say why.
The term Artificial Intelligence has changed its meaning many times over the last 50 years. It currently refers to systems that can do feature correlation and extraction from training data sets--often very large ones. For example, training a system to recognize a face (like your phone does) is an exercise in presenting exemplar data to the system along with reinforcing feedback when a face is dsiplayed. This is called supervised training. After seeing enough faces and getting the green light for each one, the system can learn a correlation and provide the green light on its own when a new face is presented.
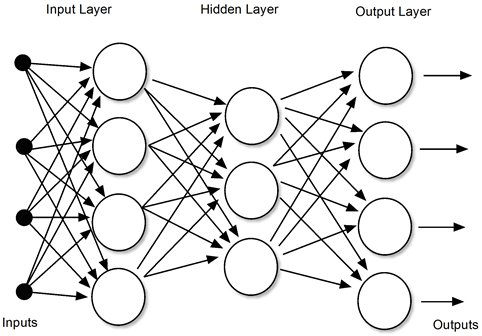
The systems and theory for this kind of AI have been around since the 1960s--even the 1950s. A well-known example is called a multi-layer perceptron, or neural network. The original objective was to imitate the way neurons interconnect and to reinforce pathways in the presence of specific stimuli. The neural network would be made of two or often three layers--an input layer, a hidden layer and an output layer. Inputs to a given layer would add or subtract from one another in accordance with weights (multipliers). The weights would be "learned" during the training process. They were the jelly in the Martian's brain.
The neural network is an analog model of how neurons might work, and some analog implementations have been created. On a digital computer, however, it is represented by matrix arithmetic. Matrix arithmetic can often be parallelized so that multiple operations occur at the same time. This makes it fast—very fast--given suitable hardware.
In the last ten years, supercomputers have been teased up, not from liquid-cooled Crays or hypercubes, but from very small-featured computing devices like field-programmable gate arrays or graphics cards. In fact, Nvidia--the company that makes the some of the best graphics hardware--is also the world's leader in supercomputers. That's because Nvidia graphics cards are hyper-parallel, and they can be programmed to do AI just as well as to perform pixel-based ray tracing. Nvidia is currently building what will be the world's largest supercomputer in Britain.
In the network business, you see "AI" being applied to network analytics, intrusion detection and diagnostics. The systems are the product of supervised and unsupervised training that look to correlate events and to recognize unique patterns—such as a network intruder. Part of the reason why vendors are pushing the cloud so vigorously is in addition to being the customer, you are part of the product; your network experiences contribute the training sets for "AI" analytics. They need you to participate in the cloud, too.
Given copious compute power, the quest to make AIs more capable is correlated with making them deeper--adding more layers, more sophisticated back-propagation and weight adjustment. "Deep learning" makes the AI more powerful, but it also makes it subject to pitfalls that are endemic to higher order curve-fitting. That is, when the input is similar to training data, the results can be excellent. In the face of unfamiliar input, deep AI can be wildly unpredictable. "Curious," as Pierce Brosnan would say. And it’s coming to your network.
-Kevin Dowd